
1·
49 minutes agoGive CodeBerg a look. It’s starting to pick up some steam.
Give CodeBerg a look. It’s starting to pick up some steam.
keyword detection like “Hey Google” is only used to wake up a device from a low power state to perform more powerful listening
That’s more applicable for something like a Google Mini. A phone is powerful enough, especially with the NPU most phones have now, to perform those detecting efficiently without stepping up the CPU state.
Is there some kink of roleplaying AI dev?
Is there some kink on your side in pretending you’re smart? You have no idea who I am or what I know.
Increasing the number of keywords to thousands or more (which you would need to cover the range of possible ad topics) requires more processing power
Again, you’re showing your lack of knowledge here. A model doesn’t use more power if trained on one class or a hundred. The amount of cycles is the same in both instances.
It’s usually smart speakers that have a low powered chip that processes the wake word and fires up a more powerful chip. That doesn’t exist in phones.
Edit: just to hammer home a point. Your example of “hey Google” simply waking up the device for more complex processing just proves my point. The scenario we’re talking about is the same as the wake word. We’re not looking to do any kind of complex processing. We’re just counting the number of times a word is triggered. That’s it. No reasoning out the meaning, no performing actions, no understanding of a question and then performing a search to provide a response. It’s literally a “wake-word” counter.
I don’t have any questions. This is something I know a lot about at a very technical level.
The difference between one wake word and one thousand is marginal at most. At the hardware level the mic is still listening non-stop, and the audio is still being processed. It *has" to do that otherwise it wouldn’t be able to look for even one word. And then from there it doesn’t matter if it’s one word or 10k. It’s still processing the audio data through a model.
And that’s the key part, it doesn’t matter if the model has one output or thousands, the data still bounces through each layer of the network. The processing requirements are exactly the same (assuming the exact same model).
This is the part you simply do not understand.
Just because you dont understand
Lol. My dude, I’m a developer who specializes in AI.
It would cost trillions
I have no clue how you came to that number. I could (and partially have) whipped up a prototype in a few days.
half the battery life
Hardly. Does Google assistant half battery life? No, so why would this? Besides, you would just need to listen to the mic and record audio only if the sound is above a certain volume threshold. Then once every few hours batch process the audio. Then send the resulting text data (in the KBs) up to a server.
The average ad data that’s downloaded for in-app display is orders of magnitude larger than what would be uploaded.
there are plenty of people that can find shit in the noise on wireshark
How are they going to see data that’s encrypted and bundled with other innocuous data?
Nevermind the why (I’m not entirely convinced it’s being done), I want to know what exactly would be seen in network traffic.
Ok, you said “voice collection” which I’ll assume is audio recording and then uploading to some server. That’s an astonishingly bonkers and inefficient way of doing it. You run a very small model (using something like Tflite) that’s trained against a few hundred keyboards (brand names, products, or product category) and run it on the background of your service. Phones already do essentially this with assistant activation listening. Then once a few hours of listening, compress the plain text detection data (10 MB of plain text can be compressed to 1 MB) and then just upload the end result. And we wouldn’t be talking about megabytes, we’d be talking single digits kilobytes. An amount that wouldn’t even be a blip on wireshark, especially since phones are so exceedingly chatty nowadays. Have you actually tried to wireshark phone traffic? It’s just constant noise.
It’s entirely possible to do. But that doesn’t mean that it is being done.
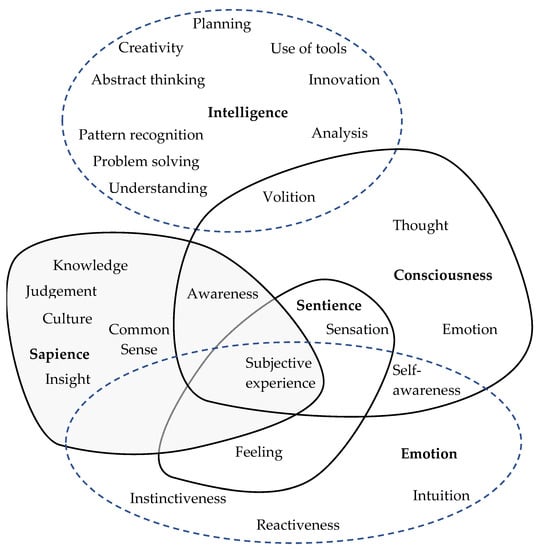
You’re citing an image from a pop culture blog and are calling it science
I was being deliberately facetious. You can find similar diagrams from various studies. Granted that many of them are looking at modern AI models to ask the question about intelligence, reasoning, etc. but it highlights that it’s still an open question. There’s no definitive ground truth about what exactly is “intelligence”, but most experts on the subject would largely agree with the gist of the diagram with maybe a few notes and adjustments of their own.
To be clear, I’ve worked in the field of AI for almost a decade and have a fairly in-depth perspective on the subject. Ultimately the word “intelligence” is completely accurate.
Ok, real question: what exactly would show up in network traffic?
Yes, but also no. You’re underestimating advertisers’ greed for data.
It’s actually trivial nowadays to build a background service like that.
So you’re saying your car is able to use mph when in the US? Fancy car!
Btw, I was trying to make a joke about mph being some different kind of “fuel” that’s not compatible with kph, in case that wasn’t clear.
How are you doing kph in the US?
https://www.mdpi.com/2079-8954/10/6/254
What is this nonsense Euler diagram?
Science.
Did AI generate this?
Scientists did.
You mean arguing with people who show you’re wrong? Good move.
It’s not a requirement to have all those things. Having just one is enough to meet the definition. Such as problem solving, which LLMs are capable of doing.
That’s the same as arguing “life” is conscious, even though most life isn’t conscious or sapient.
Some day there could be AI that’s conscious, and when it happens we will call that AI conscious. That still doesn’t make all other AI conscious.
It’s such a weirdly binary viewpoint.
Ok. I won’t.

No, it’s because it isn’t conscious. An LLM is a static model (all our AI models are in fact). For something to be conscious or sapient it would require a neural net that can morph and adapt in real-time. Nothing currently can do that. Training and inference are completely separate modes. A real AGI would have to have the training and inference steps occurring at once and continuously.
Education was always garbage though. It is designed to generate obidient wage slaves.
in the US
Fixed that for you
You have that backwards. People are using the colloquial definition of AI.
“Intelligence” is defined by a group of things like pattern recognition, ability to use tools, problem solving, etc. If one of those definitions are met then the thing in question can be said to have intelligence.
A flat worm has intelligence, just very little of it. An object detection model has intelligence (pattern recognition) just not a lot of it. An LLM has more intelligence than a basic object detection model, but still far less than a human.
You might want to look up the definition of intelligence then.
By literal definition, a flat worm has intelligence. It just didn’t have much of it. You’re using the colloquial definition of intelligence, which uses human intelligence as a baseline.
I’ll leave this graphic here to help you visualize what I mean:
It’s not gamification that’s the issue. That aspect really held my attention and gave me consistency.
It’s the push to a pay-to-win model that made me quit. They made the challenges harder and harder to complete without using boosts, and to use the boosts you had to use gems. And gems were really hard to get unless you bought them with real money. It doesn’t matter if you have a super subscription (or whatever it’s called), you still had to pay to get the gems.
And the prices for the gems were just as predatory and the disgusting mobile gaming industry. Never should there be an option to spend over $20 for in-game consumables, nevermind over $100. It’s sick.